|
|
|
 |
|
|
|
|
|
|
 |
|
|

丂巹偨偪偼墶昹巗偵廧傫偱20擭偵側傝傑偡偑丄悈摴偺悈偼晄枴偔偰堸傔偨傕偺偱偼偁傝傑偣傫丅媥擔偵側傞偲晇偲嶳棞導偺摴巙愳傑偱傢偒悈傪媯傒偵弌偐偗偰偄傑偡丅堦夞偵億儕僞儞僋3屄偔傜偄傪媯傫偱婣傝傑偡丅偦偺傑傑偱偼堸傔傑偣傫偑暒偐偟偰僐乕僸乕偵偟偨傝峠拑偵偡傞偲丄悈摴悈偱偼枴傢偊側偄摟偒捠偭偨旤枴偟偄悈偵側傝傑偡丅儂儞儌僲偺悈傪堸傒偨偐偭偨傜丄懡彮偺嬯楯偼惿偟傓傋偒偱側偄偲巚偄傑偡丅
丂偙偆偟偨帺桼婰弎暥傪変乆偺乽擔杮岅僙儅儞僥傿僋僗乿偱偼堄枴偺捠傞暥愡偱僇僢僩偟傑偡丅宍懺慺偲偄傢傟傞媽幃偺僇僢僥傿儞僌偱偼抁偄扨岅偵側偭偰偟傑偄堄枴偑揱傢傜側偔側傞偨傔丄偙傟傪夵椙偟傑偟偨丅
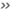 巹偨偪偼墶昹巗偵廧傫偱偄傞 巹偨偪偼墶昹巗偵廧傫偱偄傞 |
| 悈摴悈偼晄枴偄 |
| 堸傔偨傕偺偱側偄 |
| 媥擔偵嶳棞導偺摴巙愳偵弌偐偗傞 |
| 悈傪媯傒偵弌偐偗傞 |
| 僐乕僸乕傗峠拑偲偟偰堸傓 |
| 傢偒悈傪暒偐偡偲旤枴偟偄悈偵側傞 |
| 儂儞儌僲傪枴傢偄偨偄 |
| 嬯楯偼惿偟傓傋偒偱側偄 |
丂偙傟傪宍懺慺偱僇僢僩偡傞偲柵拑嬯拑側扨岅偺梾楍偲側傝傑偡丅僇僢僩偟偨傕偺傪弴斣偵暲傋偰撉傔偽丄傑偩壗偲偐棟夝偱偒傑偡偑丄僇僢僩偝傟偨扨岅偑暲傋姺偊傜傟偰偟傑偆偲慡偔堄枴偑捠偠側偔側傝傑偡丅師偺扨岅偱偡乮徫乯丅
| 悈摴 |
媯傓 |
| 堦夞 |
晇 |
| 偦偺傑傑 |
傢偒悈 |
| 悈摴悈 |
億儕僞儞僋 |
| 墶昹巗 |
晄枴偄 |
| 儂儞儌僲 |
旤枴偟偄 |
| 弌偐偗傞 |
婣傞 |
| 摴巙愳 |
摟偒捠偭偨 |
| 峠拑 |
僐乕僸乕 |

丂僥僉僗僩儅僀僯儞僌偺栚揑偺偆偪偵丄戝検暥彂偐傜撪梕傪梫栺偟偰乽傑偲傔傞乿偙偲偑偁傝傑偡丅偍媞條偺惡傪暦偄偰宱塩帒尮偵妶梡偟偨偄偲偺婜懸偼戝偒偔丄崱屻傑偡傑偡戝検暥彂傪撉傒庢傞偙偲偑媮傔傜傟傑偡丅
丂偲偙傠偑恖娫偺栚偱撉攋偡傞偲偄偭偰傕丄幚嵺傗偭偰傒偨曽偼偍傢偐傝偱偟傚偆偑戝曄側嶌嬈偱偡丅堦夞偩偗側傜傑偩偟傕丄偙傟偑壗搙傕偁傞傛偆偩偲丄偮偄扤偐偵棅傒偨偔側傝傑偡丅攈尛偺僷乕僩偝傫傗怴擖幮堳偵傑偐偣偰偟傑偄傑偨偔側傝傑偡丅偟偐偟丄斵傜偩偭偰僣儔僀傕偺偼僣儔僀丅
丂偙傟傪宍懺慺偱僠儍儗儞僕偟偰偄傞偺傪尒傑偟偨偑暚斞儌僲偱偟偨丅
丂傢偢偐600恖偺暥復傪僂儞僂儞偲丄挿帪娫偐偗偰扨岅僇僢僩偟偰暲傋傛偆偲偟傑偟偨偑丄寢壥偼忕択偺傛偆側傕偺偵側傝傑偟偨丅
| 偙偺 |
戝偒偄 |
僐乕僙乕 |
愇尣 |
| 朅 |
旤敀 |
DHC |
偍偡偡傔 |
| 悈 |
僇僒僇僒 |
墭傟 |
攦傢側偄 |
| 僣儖僣儖 |
偟偭偲傝 |
旂帀 |
傂傝傂傝 |
| 枮懌 |
捝偄 |
僯僉價 |
抣抜 |
| 偮偭傁傞 |
弫偄 |
崄傝 |
姡憞敡 |
| 僟儊 |
傂偺偒 |
儕僺乕僩 |
晄枮 |
丂偙傟傜偺扨岅傪慄偱寢傫偱丄偦傟偧傟帺暘偱撉傫偱壓偝偄偲偄偆偺偱偡丅
丂偣偭偐偔僇僢僩偟偨傕偺傪嵞搙寢傫偱偄偗偽乽壗偐堄枴偑弌傞乿偲偄偆偺偱偟傚偆偐丅偱傕丄偦傟偱偼庡娤揑偵側偭偰偟傑偄傑偡丅偍媞條偺惡傪暦偔偺偱側偔丄帺暘偨偪偺堄尒傪嶌偭偰偄偔偙偲偵側傝偐偹傑偣傫丅
丂巹偨偪偺乽傑偲傔暥乿偼偙偆側傝傑偟偨丅
| 旂帀傑偱棊偲偡仺姡憞敡側偺偱仺捝偄仺傂傝傂傝 |
| 傂偺偒偺愇尣仺崄傝偑傛偄仺枮懌偱偡仺儕僺乕僩偟傑偡 |
| DHC仺僣儖僣儖仺僯僉價偑徚偊傞仺墭傟棊偪偑傛偄仺抣抜偑崅偄 |
| DHC仺旂帀傑偱棳偡仺偮偭傁傞仺僇僒僇僒仺攦傢側偄 |
| 僐乕僙乕仺朅棫偪偑偄偄仺偍偡偡傔仺旤敀岠壥偑偁傞 |
丂偄偐偑偱偡偐丅9愮恖偱偁傠偆偲2枩恖偱偁傠偆偲丄敪尵偟偨恖乆偺堄尒傪傑偲傔偰寢榑傪偩偟傑偡丅偙偙偱偼5偮偺梫栺暥偑偱偒傑偟偨丅
丂媽幃側宍懺慺偺傑偲傔偱偼丄扨岅偲扨岅傪慄偱寢傫偱偐傜丄彑庤偵偮側偄偱撉傫偱偔傟偲偄偆椻偨偄僒乕價僗偱偟偐偁傝傑偣傫偱偟偨丅偟偐偟丄慻怐妶惈壔尋媶強偺梫栺暥偼堄枴偺偮側偑傞傑偲傔曽傪偟偰偔傟傑偡丅
丂偟偐傕丄傑偲傔偨5暥宆偵僺僢僞儕敪尵偟偨恖乆偺堄尒偼偙偆偱偡丅偪傚偭偲僘儗偨曽岦偵棳傟偨恖乆偺敪尵偼偙偆偱偡丅偁傞偄偼慡偔儐僯乕僋側n=1偺傛偆偵屄恖揑側敪尵傪偟偨恖偺堄尒偼偙傟偙傟偱偡丄偲撪梕偐傜暘椶偟偰偔傟傑偡丅
丂偦偺偨傔丄暥宆偛偲偵廤拞偟偰撉傒崬傓偙偲偑偱偒傑偡丅偄傠偄傠側敪尵傗庡挘偑僶儔僶儔偵弌偰偔傞偺偱側偔丄仜仜僞僀僾偺堄尒偲偐亊亊僞僀僾偺堄尒偲偟偰偔偔傜傟傑偡偐傜丄棟夝搙偑怺傑傝傑偡丅
丂2枩恖偺敪尵偺偆偪丄A偲偄偭偨恖乆偑4愮恖偄偰丄B偲偄偭偨恖偑6愮恖偄傑偟偨丅A偺垷棳偑偙傟偩偗偄偰丄B偺垷棳偑偙傟偩偗偲偄偭偨傛偆偵側傝傑偡丅
丂A偵傕B偵傕擖傜側偄屄惈揑側敪尵幰偼3愮恖偄傑偟偨偲丅

丂宍懺慺偱僩儔僀偟偰偄傞恖乆偺嶌惉偡傞僌儔僼傗恾偼丄摑寁妛傗悢妛偱張棟偝傟偰偄側偄偺偱丄僨乕僞偲偟偰嵞棙梡偱偒傑偣傫丅婥暘偱嶌偭偨乽偍奊偐偒乿偺傛偆側傕偺偱偡丅
丂偦偺揰丄乽擔杮岅僙儅儞僥傿僋僗乿偼慡偰摑寁妛偱暘愅偝傟偰偄傞偺偱丄栚揑偵墳偠偰僗僐傾乕傪妶梡弌棃傑偡丅憡娭學悢傗場巕摼揰丄偦偟偰婋尟岆嵎棪側偳偑偟偭偐傝寁嶼偝傟偰偄傑偡丅偪側傒偵婋尟岆嵎棪偼0.1%悈弨偱偡偐傜丄暍傞婋尟惈偼1000夞偵1夞枹枮偲偄偆妋幚側儗儀儖偱偡丅 |
|
|
 |
|
|
|
|
|
|